自己紹介
- 大学の研究室でデータ解析やってます
- 昔はC++やJavaも好きでしたが、最近は全部Python
- 純粋な関数型言語はあまり使ったことありません
2016/5/31までの30%OFFクーポンはこちらから。
https://www.udemy.com/python-jp/?couponCode=minpy1605
「モナ・リザ」
レオナルド・ダ・ビンチ作(1503年〜1519年頃?)

なぜ、この絵画はこれほどまでに有名なのか?
1つの解釈がココに

- モナ・リザが有名になったのは、20世紀に入ってから
- 16世紀の作品
- 1911年盗難に遭う
- 2年後奇跡的に発見
- その後、2度の犯罪被害
- 暴漢に酸をかけられたり、石を投げられる
- 1919年に初めて風刺画題材に
- その後、数百の模写が作られ、数千の広告に利用される
そう!
モナ・リザが有名なのは、偶然の差物
あるものAがブームになるメカニズム
- そのときの社会の状態など、いくつかの偶然が重なる
- Aと似たもののなかで、Aに注目が集まる
- Aがすごいとみんなが思う
- ブームになる
- データ解析にRは便利
- 軽量スクリプト言語としてPerlの歴史は長い
- Rubyも素晴らしい
なぜ、Python?¶
もはや理屈では無い!
Pythonはモナ・リザでいう20世紀の一大ブームの前夜にいる!!(気がする)
今日は、Pythonから見た関数型言語のお話
プログラミング言語には、いくつかの考え方(パラダイムがある)
手続き型(imperative)
オブジェクト指向型(object-oriented)
関数型(functional)など
 Pythonはマルチパラダイム言語
Pythonはマルチパラダイム言語
http://www.slideshare.net/paulbowler/periodic-table-of-programming-languages-13738602
Software Design 2015年8月号 (技術評論社)
なぜ関数型プログラミングは難しいのか?

純粋な関数型言語は、あまりにも考え方が違う!
Hakellの本格的な入門書
関数型プログラミングの解説書として分かり易いと思います。

全381ページのこの本。
画面に文字を表示する「Hello world」プログラムが出てくるのは、なんと260ページ目!
他にも例えば・・・
変数の値を変えるような代入(破壊的代入)が出来ない
a = 1
b = 2
a = b + 1 # だめー
なぜ、そんなことに?
そもそも、関数型言語とは?
関数を使ってプログラムを作る!
Pythonにも関数はある
関数型言語の関数と何が違うのか?
# 引数に1を足して返す関数
def func(a):
return a+1
func(3)
# Pythonではこれも関数
a = []
def func():
a.append(1)
func()
print(a)
# これも、間違いではない。
age = {'Taro': 10}
def func():
age['Jiro'] = 8
print(age)
func()
print(age)
関数は「引数」をとって「戻り値」を返すというのが基本
外の世界に影響しちゃダメ
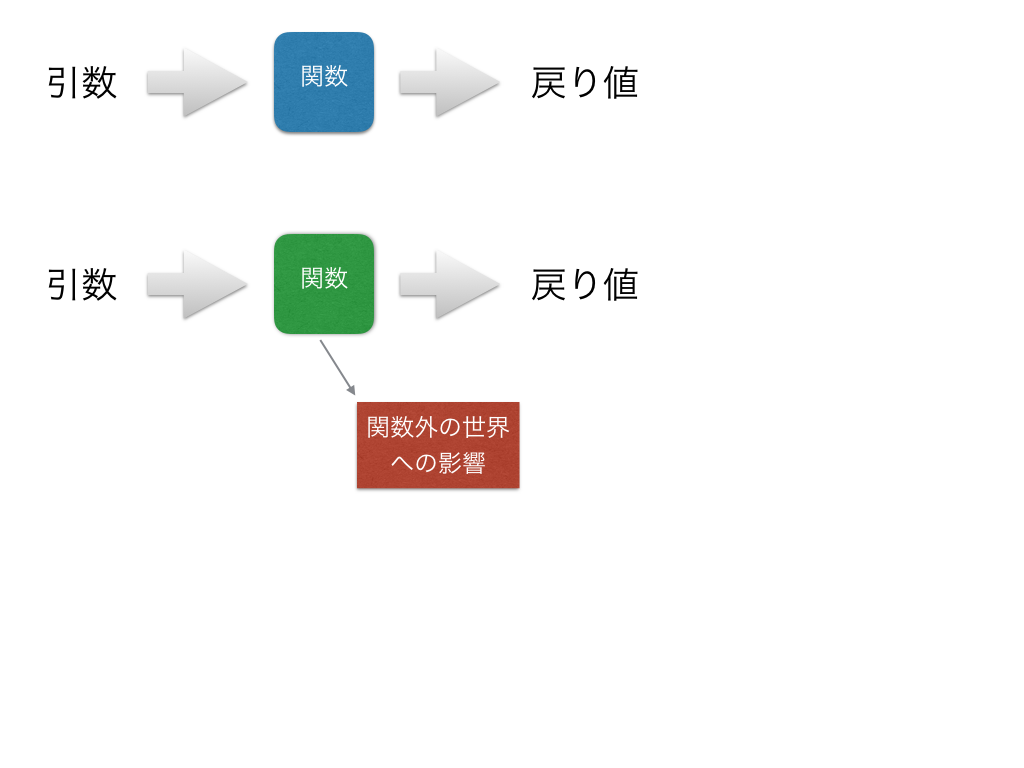
データ解析の実際の例から、関数型的な考え方を見ていきます
あくまで、「的な」です
# 必要なものをimport
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# サンプルデータの準備関数
# n行m列のランダムなmatrix
def initialize(n = 50, m = 10):
avg_rand = np.random.randint(0, 20, n)
std_rand = np.random.uniform(0.5, 10, n)
_d = [np.random.normal(avg, std, m) for avg, std in zip(avg_rand, std_rand)]
data = pd.DataFrame(_d, index=['var{}'.format(i) for i in range(n)],
columns=['sample{}'.format(i) for i in range(m)])
return data
# 可視化
data = initialize()
sns.heatmap(data)

# 行方向(var)のデータのバラツキ
_hist = plt.hist(data.std(1))

# バラツキの大きな行だけを残す
data = data[data.std(1) >= 6.0]
# (ちなみに)破壊的代入恐るべし。dataが書き換えられる。
# 可視化
sns.heatmap(data)

# 行方向に標準化
# 平均を引いて、標準偏差で割る
m = data.mean(1)
s = data.std(1)
data = data.subtract(m, axis=0).divide(s, axis=0)
# 可視化
sns.heatmap(data)

# コードをまとめると
# 初期化
data = initialize()
# バラツキの大きいデータを取り出す
data = data[data.std(1) >= 6.0]
# データを標準化する
m = data.mean(1)
s = data.std(1)
data = data.subtract(m, axis=0).divide(s, axis=0)
関数型言語の考え方に近付いてみる
# 関数にする
# バラツキの大きいデータを取り出す
def var_filter(_data, threshold=6.0):
return _data[_data.std(1) >= threshold]
# データを標準化する
def standardize(_data):
m = _data.mean(1)
s = _data.std(1)
return _data.subtract(m, axis=0).divide(s, axis=0)
data = initialize()
temp = var_filter(data)
temp = standardize(temp)
sns.heatmap(temp)
# 分かり易いけど、なんかダサい

sns.heatmap(standardize(var_filter(initialize())))
# ちょっとカッコが増えすぎ・・・

# そこで、pipe!
# 関数の連続的な適用が可能
initialize().pipe(var_filter).pipe(standardize).pipe(sns.heatmap)

- pipeは、Pandas0.16.2で追加された機能
- Rのmagrittrの影響を受けているらしい
- magrittrは、F#の影響を受けている模様
initialize().pipe(var_filter).pipe(standardize).pipe(sns.heatmap)
# 1つの注目点、関数の引数と戻り値が同じ型(DataFrame)になっている
他の部分に影響を与えず、仕様変更が容易にできる
initialize().pipe(var_filter).pipe(standardize).pipe(new_func).pipe(sns.heatmap)
Webアプリの開発などにも応用できる
How to design and code a complete program http://fsharpforfunandprofit.com/posts/recipe-part2
まとめ
- 関数は引数をとって戻り値を返す
- 外部に影響を与えない関数の方がいい
- データ型を統一すると見通しがよい関数の合成が可能
- 関数型の考え方を意識すると、よいプログラムが書けそう